
The Late-Night Texts Start Again
Adam: Hi, I’m Adam Gordon Bell, and this is CoRecursive, and today I have here again, Don.
Don: Hi, I’m Don McKay, and I’m here again.
Adam: So I’ve been texting you again.
Don: Yes. Yeah. And it’s always late too. It’s never like, you know… It’s 10 o’clock at night or something.
Adam: I know. Sorry.
Don: I mean, when you’re like an old man like me, that’s late.
Adam: It’s too much. Yeah, you’re like, “I eat at 4:00, I go to bed at 8:00.” Yeah.
Reward Is Enough: The Claim
Adam: So I’ve been trying to understand, I guess, machine learning, and that’s why I sent you some things. So, what did I send you?
Don: First you told me you didn’t have whiskey anymore, and I was like, “That’s a crime.” And then you said, “Okay, I’ve been continuing going deep on AI and ML stuff. I’m trying to understand it at a level of, could I write a program that’s just normal ifs and loops and whatever, but yet it can learn? And I think I found the key. It’s this paper, ‘Reward is Enough,’ Silver, Singh, Precup, Sutton, 2021. I wanna explain it to you. It’s sort of simple.” And simple my knee quotes.
Adam: And yeah, because okay, machine learning is fancy and cool, and like we’re software developers, we should be able to understand it. But it feels like magical.
Don: It’s like existential, right?
Don: You’re like, “Oh, I don’t know. I don’t know how it works, so Yeah. I was like, “Oh, okay.” Here’s the important line:
Intelligence and its associated abilities could be understood as subserving the maximization of reward.
Adam: Like what, what do you think? Subserving is such a weird word.
Don: Yeah, you haven’t heard of subservient individuals?
Adam: Well, I guess, okay, maybe in that context.
Don: It seems like he’s saying that as long as you have a reward structure, you can create intelligence, which I think is a little bit reductive, in my opinion.
Adam: I mean, it’s incredibly reductive, right?
Don: Yeah.
Adam: Saying it all reduces.
Don: It all reduces down.
Adam: Completely.
Don: The maximization of reward, right? And furthermore, saying intelligence and its associated abilities can be understood by subserving of reward, which means everything about our intelligence is just serving some kind of reward structure. And I think that that’s kind of an… I don’t know. It’s very reductive. Once you reduce something to that level, you lose the fidelity of the statement, right?
Adam: So it reduces everything… … But it has a cool title, right? Because that sentence is very complex. But the, the title of the paper, right? “Reward is Enough.” You kinda get what he’s saying, right? W-
Don: Wanted to create an artificial intelligence, reward is enough.
Adam: Yeah.
Don: That’s the only structure that you.
Adam: It’s everything. Yeah, that’s all you need is just that one thing, right? I’ve reduced the entirety of intelligence, of intellect, of culture, of… I mean, I guess he didn’t say culture, but everything to do with what makes something intelligent and smart and able to take action in the world, is just reward, right?
Adam: Press the lever, get a piece of cheese, basically. Okay. So, Sutton, he wrote this book on reinforcement learning and him and his advisor kind of invented this field.
Adam: So I just wanna pull it apart, right? That’s what I wanna talk about today. I was like, this is a great thing for our kind of, stack trace format, which I asserted before and maybe still needs a better name that we take something and kind of back up the stack frames until you get, right? We have this really grand statement, like can we pull it apart? Can we get to somewhere?
Don: Null pointer exception.
Adam: Yeah. Turns out it was all intelligence is a null pointer exception, gone the bonkers.
Skinner’s Pigeons Built This Idea
Adam: Okay, so it’s 1988 and Richard Sutton is finishing his PhD at the University of Massachusetts, and his advisor is named Andrew Barto. And Barto, he actually comes from B.F. Skinner was his background as a academic. Do you know B.F. Skinner?
Don: I do not.
Adam: So interesting enough, right? B.F. Skinner, he taught pigeons things where they would press a lever and they would get like a little piece of thing.
Don: Yeah.
Adam: He’s the person who operationalized how to like train animals to do things based on reward. And like his theory was also that all of human behavior is based on, you know, going after rewards, like the same way your dog wants a treat it’s kind of a weird background. Sutton is like a computer scientist, but he’s working under this guy whose background is this behaviorist and who taught pigeons basically.
Adam: And side note, ’ Skinner is super interesting, probably not a topic for the podcast, but Skinner in World War II, he built things for the US military. Any guesses what they would be?
Don: Homing pigeons.
Adam: Y- y- yeah. So he built a missile guidance system where they just put the pigeons….
Don: Put the pigeons in the missile. I did actually see like a video about that, yeah.

Adam: It’s insane, right? He had a very reductive view, as you would say. He reduced everything to like, “Well, yeah, let’s just… We need to hit this target. Why don’t we just train a pigeon.
Don: Yeah.
Adam: To like…”
Don: Were good at.
Adam: And he also had, or like one of his students built, I wrote this down. This guy who worked for him named Thom Verhave had a pigeon product or project at the company, E… Is it E. Lilly? Is that how you say it? The drug company, E. Lilly.
Don: I think it’s E- think it’s Eli Lilly.
Adam: He had this project at this company where basically they just had pigeons do QA. So all the, the parts are going down the aisle, and they just have pigeons there who are trained to look for the, the broken ones and peck them out of there. So they tried to basically re- they replaced human workers with pigeons.
Adam: And like they got the whole thing working, and then they canceled it because they thought it would be like a PR disaster. Although I did hear a story before that they canceled it because it was very demoralizing. Imagine you’re at your job and they fire the guy like further down the chain from you.
Adam: Like further down the…
Don: Just replace them with a.
Adam: Replace him with a pigeon. Like you, this is the worst. So it didn’t take off. But same idea, right? You just give a simple reward. The pigeon learns like, “Oh, this is a defective part,” or, “This is a defective pill,” and knocks it off. Anyway, this is behaviorism. Anyways, that’s where the Skinner guy came from, … And Sutton’s working under him, but the whole computer science thing at this time in 1998 was very different, right? It was AI, but a different approach to AI, expert systems.
Adam: So expert systems, they sometimes call Good Old-Fashioned AI expert systems, was this idea of AI was, like, different than today. It was if you could interview a doctor and figure out how he assess a patient, and you can just write down all those rules, And then ask people about their health, and then it’s like a doctor in a box ‘cause it’s just like a flowchart that you can travel through.
Adam: I mean, it seems kind of basic right now, but they had this idea, if we can get all the rules for all of intelligence written down, right? Here’s all the doctor rules, here’s all whatever. We can replace… We can have intelligence just in sort of if statements and whatever.
How Tic-Tac-Toe Teaches a Machine
Adam: So Sutton’s not that, right? He works for this behaviorist different approach, and, he publishes a paper called “Learning to Predict by the Methods of Temporal Differences,” and it’s a super cool idea I’m gonna show you, ‘cause this is how I started to understand machine learning, right?
Don: X’s and O’s.
Adam: So this is tic-tac-toe, right? And this is how he explains the thing, right? So if we play tic-tac-toe, you go first, so you’re, you’re X. You can pick which position you want But this is all the possible states of the entirety of the game in this tree.
Don: It’s just a giant chart with a bunch of X’s and O grids and what the current state of them would be. Very similar to chess moves kind of like mapping.
Adam: It’s kind of like a tree, right? Or a flowchart, so his idea is, okay, there’s tic-tac-toe. He figured it out. There’s, I think it’s like 725 possible states that you can be in, right? And then at the very end, you have a result, right? So if we played this game where you get three X’s across and I do nothing to stop you ‘cause I don’t understand the game then he, he gives that a value.
Don: So, he’s assigning values to win conditions so that, know, that’s what you wanna get. That’s the, that’s the ideal state.
Adam: It’s like there’s no magic. It’s like an array of 725 values. A game and you put an X and I put an O, and so it’s a tree going down. And at the end I win, right? So here’s this trick. This is, this is like the whole of the thing. And then all he does is this, right? So this one must be negative one because Adam wins.

Adam: And then so this one, he goes backwards and he’s like, “Okay, this one is like negative .1,” right? And then this one is negative .01 and so on. Going backwards and saying like, “Well, those must have all been pretty good ‘cause you won,” They’re not as good as the part that you won, but they’re, they’re kind of good. So it’s basically like walking backwards. It’s like how people develop superstitions in a way, right?
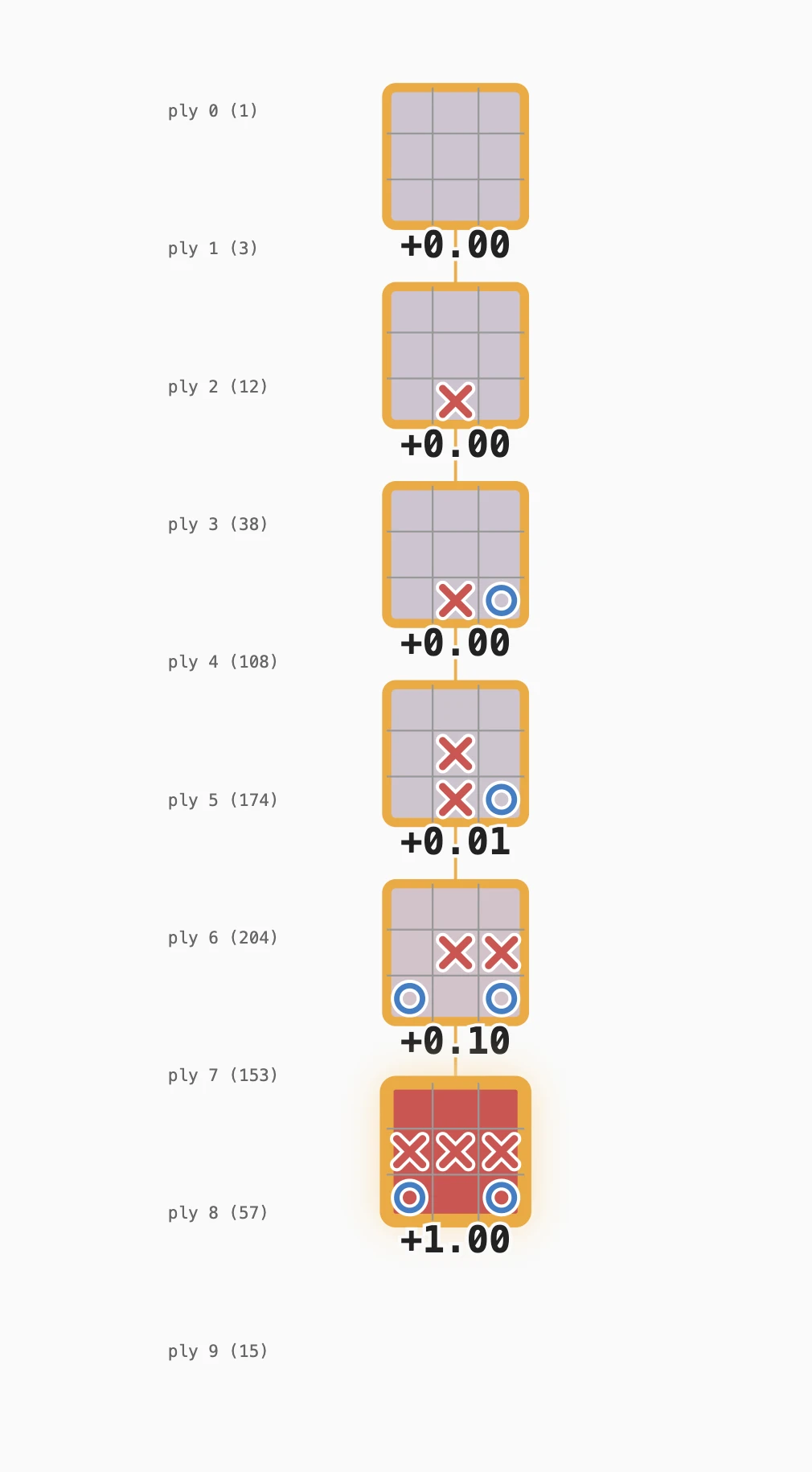
Don: So you trace back the path to how you got there, and you assign values according to how much you wanna incentivize that path based on the end result or decentivize that path based on a losing condition. So at the end of the day, when every possible move has a value, you’ll know how to respond according to always going towards the one that will give you more of a score.
Adam: Exactly. This is his whole paper. I think you just nailed it, right?
Don: So whatever choice you make, it will then evaluate all of the other choices that it’s learned, and then it will have a score, and it will go with the one with the highest score.
Adam: So if I go play, so that was play one game, right? If we go play 10 games, every time it goes through the tree, it decides if it wins, so it’s like, hey, play a whole bunch of tic-tac-toe games and see where you won and where you lost. You don’t even have to know how the game works, you don’t even need to know what’s good and what’s bad.
Don: Just need to be able to play it many times so you can start, building it like a model of scores.
Adam: Yeah, and if you do enough times, … You start to know what the values are, like what’s a good move and what’s a bad move. This is his whole thing, right? This is like his early paper, and I love it because it, it just explains this simple version of machine learning, right? It’s learning to play the game, just by doing this working backwards step.
Adam: And there’s no crazy stuff, right? It’s just a bunch of array values and you’re like updating. It’s like if at the end of the day you get told you did good or bad, then you just figure out during the day what were the things and work backwards.
Don: Yeah. No, that’s, amazing.
Adam: And that’s part of his reward is enough, right?
Don: Yeah.
Adam: All you need to do…
Don: Is assign a score to desirable or undesirable outcomes.
TD-Gammon Shocks the Experts
Adam: So what happens next?
Don: He moves up to chess.
Adam: Not yet, but we’re gonna get there. Four years later, 1992, somebody picks up his paper, and it’s this guy at IBM, Watson Lab, and he does backgammon, which was kind of a interesting. Backgammon people are super into backgammon, but I don’t think it has the allure of chess, right?
Don: It doesn’t have the pedigree of chess?
Adam: You know, the backgammon involves gambling often too, like you’re betting on it. I don’t know. Old British men play it, I guess. I don’t know who.
Don: Yeah, I know my mom played backgammon all the time.
Adam: But it is like a complicated game, right? And it has some interesting… So the guy who decides to work on it, his name is Gerald Tesauro, and he’s at IBM Watson. And he just takes that rule, right? Which Sutton calls the temporal difference update. But there’s a problem with backgammon versus tic-tac-toe. Maybe a problem versus every single game in the world versus tic-tac-toe. Do you know what it might be? they’re just bigger. Tic-tac-toe is so small.
Don: Well, the… Oh, you mean like the possible outcomes?
Adam: The possible outcomes is just astronomically larger, right? So tic-tac-toe, it’s great for his paper ‘cause there’s like less than 800 states.
Adam: But yeah, do you wanna guess on the backgammon number?
Don: I have no idea.
Adam: So this says it’s 100 quintillion possible states, which are, so that would be possible game states, right? It’s if you played all possible games. If you needed to make this array to hold all the values.
Don: Of every possible position in every possible game.
Adam: Yeah. So it would be… No, that’s exactly what it is. It would be as many grains of sand on the beach of Earth, so you can’t even enumerate it, right? You can’t make an array or a hash table.
Don: You’ll need a lot of memory.
Adam: Yeah. It’s just not possible. And then, to play that game forward and backward and update those all like it would take too long, right? So he does something different. He uses a neural network. So you can imagine that we have, in our tic-tac-toe, we have like a function, say, that takes in the nine values, like your state of X’s and O’s, and then it returns a number.
Adam: He does that, but he doesn’t actually, you know, come up with that much memory. He just puts this neural network in the middle that somehow returns a value, right? And that way he can shrink the problem. So the network that he makes is tiny. It’s three layers in a neural network. A neural network has like kind of floats in it, and then some conditions that make it either return, you know, a high value or a low value.
Adam: I don’t super know how it works, but he’s using way less values than there are possible states, right? And the idea there is it’s kind of like compression, right? if you need to store all the values of the game state, but instead of having just a bazillion values, you say like, “Oh, we only have this many,” then it has to figure out what the duplicate parts are. It has to pattern match. It’s kind of like a JPEG compression, right? It’s oh, all these games are similar. We can update this little spot at once.
Don: It starts to see winning patterns from losing ones.
Adam: It just doesn’t have that much memory, much like we don’t, so it has to find ways like, “Oh, this is similar to that other time. Maybe this is like that.” But he does the same thing, right? Have this thing play backgammon against itself, and then when it gets a good result or a bad result, you know, update the value in the neural network.
Adam: So what happens? How can something actually get better when it’s just playing against itself? You know what I mean? It doesn’t know backgammon. Like, how is it gonna get good at it if it’s.
Don: Well, you get to know all the moves, right? If you haven’t played it before and you play against yourself, but you know the rules. You have to at least know what the rules are to the game. Then when you play against yourself, you start to recognize what to do in response to certain moves.
Adam: So this is a side project that he plays and he, he has this thing, like it’s 1992, computers are still pretty slow, but he’s got it off in the corner playing backgammon against itself.
Adam: … At this time, IBM Watson is this prestige lab of the AI era, like for this expert systems of writing down all the important rules, this is the preeminent place in the world. But this guy’s like doing his other thing, right? He’s taking the Sutton guy’s idea, having it run. Well, they’re all busy off working on more important expert projects. … I think you can guess what happens next.
Don: Like after they let it play with it, like play against itself for a number of, I guess, days, months? Like how long did they spend?
Adam: Hundreds of thousands of games against itself.
Don: Hundreds of thousands of games. Imagine they would’ve moved on to something else.
Adam: Well, I mean, maybe they did. But I mean, he’s a researcher, so he wanted to write a paper about it and whatever. But anyway, so he brings in backgammon players, he brings in experts, and they play it and they lose, So this thing has gotten better at backgammon than the real world players. And backgammon does have chance in it, so it’s not totally definitive, Given enough time, because I mean, this is that guy’s point. Reward is enough.
Adam: You get to the end and, oh, I lost this round against myself. Well, You know, what was the difference? And how can I… It’s the same. It’s just a bigger scale of that tic-tac-toe thing, right? It also just did interesting things. … Much like chess, there’s this whole theory behind backgammon and when you should do this and when you should do that, and what you should do in these situations. And it does different things. It hasn’t read those books. It’s just a computer program.
Don: Only knows, it only knows the data that it’s acquired by playing itself.
Adam: And so it does things playing them that they’re like, And then it beats them. And they’re like, “Oh, wait.”
Don: So it beats them because it’s unconventional. Rather than trying to imitate humans, develops its own sense of po-positional judgment by learning from experience in playing against itself.
Adam: And that’s why it was so surprising to these backgammon folk, right? They’re like, “Wow, this thing plays unusually and it’s beating us,” right? So they brought in this guy, Bill Robertie, two-time world champion, top three player alive, who had written books on backgammon.
Adam: And He says like, “Yeah, this thing is better than we are, and we were wrong about things because it beat me in these ways.” And so he’s written all these books about how to play backgammon. And so he starts updating his book, right? He’s playing against this thing, learning new moves. He’s like, “Okay, we gotta change that ‘cause it just beat me this way.” So in its unique experience of not being exposed, it’s almost like, as you said, not being exposed to humans has actually benefited it, right?
Don: Yeah. It didn’t, it didn’t learn the game framed in any kind of way. It just kind of learned it through its own experience.
Twenty Years in the Wilderness
Adam: So that was cool. They beat backgammon, and then, like you would think the next thing that happens is this takes the world by storm. But it didn’t. They just forgot about this idea.
Don: I just forgot.
Adam: Yeah. Guess for how long?
Don: Yes, I’m guessing they forgot because nobody plays backgammon, so it didn’t grab headlines to your, your layperson. But for how long? I mean, if it’s a successful project, I don’t, I wouldn’t imagine it would stay dormant for that long.
Adam: Yeah. So 20 years.
Don: 20, okay, well that was way off.
Adam: I mean, they had a much bigger project they were working on, which was Deep Blue, which like beating the chess expert and using these expert systems. And like the researchers who were building this amazing chess thing, they were like, “I don’t know, that’s just backgammon. It’s weird. Of course it works with that method, ‘cause it’s, I don’t know, who cares?”
Adam: Yeah. It’s like saying some… It’s like a result they didn’t care about, right? They’re like, “We’re not interested in this way of solving things and we’re not interested in this game.”
Don: So they just dropped it for 20 years? Yeah. Like those researchers went on to other projects?
Adam: Yeah. I mean, I’m sure some people kicked this idea around, but this wasn’t like the hotness, right? It’s like there’s probably somebody out there still really in the Macromedia ColdFusion, but that’s not the thing, right? Maybe it had some cool ideas, but who knows? And so DeepMind, they published this paper in Nature. Yeah, this is from their paper.
Don:
Perhaps the best-known success story of reinforcement learning is TD-Gammon, a backgammon playing program which learned entirely by reinforcement learning and self-play and achieved a superhuman level of play. However, early attempts to follow up on TD-Gammon were less successful.
So it’s not that they were successful and then they got shut down, it’s that they were less successful when they tried to expand beyond backgammon and they’re like, “This is a dead end.”
Adam: I guess so, and everybody gave up on it. So Sutton himself in 2017 gave a talk where he was kind of saying like WTF.
Don: Yeah. Temporal difference learning, temporal difference learning, temporal difference learning. It’s a method for learning to predict. It’s basically the center, the core of many methods you know about. Q-learning, Sarsa, TD-Lambda, Deep Q-Networks, TD-Gammon, the world champion backgammon player using deep reinforcement learning from 25 years ago. Oh my God, 25 years ago, deep reinforcement learning, 1992.
Adam: I don’t think you gave it very good emphasis, but he’s pissed off, right? It’s like he’s the guy… You get where he’s coming from, right? He’s like, “I had this thing.
Don: Yeah, I mean, He’s probably pissed because he’s like, “I did this stuff like 25 years ago and nobody gave a crap.” I mean, how often has that happened, on a very much smaller scale to a lot of programmers in the field, right?
Adam: They’re like, “Listen, our database, if we follow this trend, it’s gonna get too big. There’ll be no instance size that can hold it, and it’ll destroy our business. And I’ve worked on a solution. It’s just like, if you give me three days, it’ll save us in 18 months.” And they’re like…
Don: Three days though. No, you could be working on this other thing for three days.
Adam: Yeah.
Don: Forget about that.
Adam: And then 18 months later they’re like, “So we got this issue.”
Don: Can you like whip that up like right now?
Adam: And that’s what this guy’s like, “Temporal difference learning, like I’ve been telling you.”
Don: I’ve been telling you this for 25…
Deep Blue and the Limits of Brute Force
Adam: Yeah. So then, because what’s happening at the same time, right, is this Deep Blue thing. Deep Blue, do you remember the Deep Blue story?
Don: Yeah. I remember.
Adam: What happened with Deep Blue? Give me the, the summary.
Don: That was the one that played chess, right? And it started winning against grandmasters.
Adam: It was this big project to beat the world champion at chess as like publicity for IBM. And it was like part like, oh, they had these very big supercomputers. But a big part of it was this expert systems, right?
Don: Do you play chess?
Adam: My dad always wanted me to play chess and he like taught me, but I would just lose to him. And then I think once I left, after university I learned, and then occasionally, like when I’d go home and visit him, I would play chess against him. At one time I beat him, but I think he may have let me win.
Adam: But from, from my perspective, chess has a lot of ranges. From my perspective, he was just way better than me, but chess has so many levels, right? That I’m sure there’s tons of people, like a grandmaster, nobody can beat them.
Adam: When I learned chess, there was this idea of certain pieces of certain values, right? So it’s like you’re sitting there and you’re playing chess, and it’s like my dad’s gonna do this move where my pawn takes his pawn, and then I can take it back with my knight, but then his other pawn could take my knight, right?
Adam: And you know, oh, the knight’s more valuable. It has a value of three, and the pawn only has a value of one, so like I shouldn’t do that, ‘cause then you’re basically adding up the value of each side.
Adam: And so a big part of playing chess is like this idea. It’s like you have these pieces and you know what’s valuable, and it’s like, okay, if I make this move, then what’ll he do and what are the values, so the, the interesting thing is they’ve looked into this, right? Grandmasters actually don’t play that many moves ahead. So they might play like three or four, right? But the thing is that the m- the moves that they consider are always just the best move, which is interesting.
Don: Yeah, have names for all those.
Adam: Different opens. Yeah, and they have the open books, which is yeah, all these people who’ve played forward, the first whatever, like four or five moves on a chessboard, they’ve all been exhaustively done and they know which one is better and which one isn’t. And so Deep Blue used this strategy, right? So it had this giant open book of all, you know, the good ways to move forward. It had this giant book of end games, like if it’s just down to these couple pieces, how exactly do you win it, right?
Adam: And then instead of what I was saying of I just add up the pieces and determine the value, I mean, I guess not instead of, it had something like that, but IBM was throwing all this money at it. They brought in all these grandmasters and they came up with like the most accurate way that they could come up with to assess at this point in this game, right, what, what value, like how good am I doing, right?
Adam: And so what I described as whatever, three or four rules for adding up points, like guess what theirs was.
Don: 20.
Adam: It was 8,000.
Don: Oh, camera’s.
Adam: Like 8,000 rules.
Don: I don’t know why you ask.
Adam: Yeah.
Don: Like, arbitrary questions like, different answers.
Adam: Well, no, because it’s good. Because you said 20, and I think the thing about 8,000 is it’s absurd, right? But this was this expert system idea, right? Which.
Don: 8,000 moves in advance.
Adam: Well, so the 8,000 isn’t how many moves in advance. That’s just how they figure out for any given game position how, how valuable it is, right? It’s like you get plus one if you have this piece there, and just 8,000 different rules to say, like the equivalent of our number on tic-tac-toe that’s like, this is a .7.
Don: Scoring system?
Adam: It’s the scoring system for evaluating any specific chess move, right? And then, as you said, right? You know, we play this and we think through like, okay, if I move here, you move there, right? And then for that state, we’ll use all those rules to figure out if this is an advantage.
Adam: But then the other thing, yes, was Deep Blue was just like, I can look through a bazillion of these, right? So I have my 8,000 rules and then I’ll just play it out really quick, right? … This was in 1997, computers weren’t as fast, but it would play 200 million positions per second.
Reinforcement Learning Revived
Adam: And like it was this big boon for, for IBM, but also like for AI. They’re like, “Ah, we hit the pinnacle,” right? But in the meantime, Sutton, the, the tic-tac-toe guy, right? So he’s working on a text… Yeah, he just keeps saying that whenever you talk to him. He’s like, “Temporal,” what is it? Temporal.
Don: It was temporal difference learning, and he.
Adam: Different.
Don: Yeah.
Adam: Stuff. Yeah.
Don: Just screaming.
Adam: Yeah.
Don: In the background.
Adam: So he writes a textbook, right? Him and Barto, who’s like the behaviorist with the chickens or the pigeons.
Don: Pigeons.
Adam: Pigeons. So Reinforcement Learning: An Introduction comes out in 1998, and now, we would say it’s a very influential book. People use it and it’s important and whatever. But then it was like, whatever, IBM is a thing and Deep Blue and, and nobody cared, right? Everybody’s working on something else, right? It’s still like he’s the cold fusion guy, doing his Macromedia thing. Everybody’s like, “Dude, what, what are you doing?”
Adam: But there’s, there’s somebody paying attention, right? The thing that IBM really figured out was this searching forward, right? It’s like, “We’re moving really fast through this game, and we can figure out, you know, chase down the tree of possible moves and find the best one.” Where the Sutton guy was like, “You know, just play it to the end and then we’ll figure out who won and work backwards.”
Adam: But so somebody looks into this in 2015 Demis Hassabis. And he founded the company DeepMind. … So this is years later in 2024, he said this.
Don:
We bet on generality and learning, so those were always at the core of any techniques we would use. That’s why we triangulated on reinforcement learning and search and deep learning as three types of algorithms that would scale, be very general, and not require a lot of handcrafted human priors.
Oh, okay.
Adam: An expert in the field and I’m some guy. But so DeepMind is this company and they’re like, “We think we can reinvigorate this,” right? Like, “We think this is important.” And so they come up with these Deep Q networks. Deep Q network is just the same as the Sutton rule. It’s this idea of working backwards and applying these values, right?
Adam: And so it’s the same ingredients. There is Sutton’s update rule, and then there’s a neural network, and then there’s just a programming method, right? To like play games and put together data so that it can learn. Network with like three layers, very small.
Adam: But in the meantime, right, while all this stuff was happening, we talked about it in the LLM one actually, these dudes, like Hinton and stuff at U of T, they figured out how to make really big neural networks and learn all this stuff. And so they decide to do Atari. Basically, we wanna build an AI that can play Atari games. So they have 49 Atari games.
Adam: But they have this problem, right? Where you think of like if we do Tic-Tac-Toe, it’s like our state, you know, into our neural network or our array is easy, right? It’s like we have nine fields, like either filled out or not, right? But how do you send in where we are in a video game, into something, right? It’s hard to make a function call that’s like the current state of my video game.
Don: Yeah, because there’s too many factors.
Adam: Yeah. But just do the simplest thing.
Don: Well, I mean, like you could do something like XYZ for like coordinates or.
Adam: So they did, they took whatever the resolution of an Atari screen is, and they blocked all the pixels. So not, they wouldn’t send in a every pixel value, but they would send in say like a five by five block, every five by five block, and they put it to grayscale. So they took out the colors, ‘cause that doesn’t actually matter usually for it’s.
Don: Okay.
Adam: It’s.
Don: Like… Reduce the resolution.
Adam: Yeah.
Don: Send the pixels in.
Adam: It’s like asking it to learn with just like… But it can’t see the game. It can just see like, you know, zero, zero.
Adam: One, one, one, so the software they built, they made it play like a whole bunch of Atari games. And so it gets, its reward thing, right, is just the score. And what its input is, is like all of the pixels, and then A- Atari has a joystick. So then it’s just like it can decide, it gets in all the pixels, and then based on his joystick, it can just decide, right? I’m gonna push this way or push that way.
Adam: So this is their, this was pretty famous I think when it came out. So this is one of their videos.
Don: It’s Breakout, like a very early Atari version of Breakout. So you’ve got your paddle at the bottom, you’ve got your ball in the middle, and you’ve got rows of blocks at the top, each of them a different color.
Adam: And so this is after it’s played 100 times, right? So it’s played 100 times and learned some stuff, and it’s just trying.
Don: So the, the goal of it is always just to prevent the, the ball from slipping past you, so you’ve just gotta intercept it.
Adam: Yeah. But it has to learn that, ‘cause all it really knows is the score. It got something. It’s basically randomly moving the stick around. Okay, here’s 200. It’s more like I would play. It occasionally, it like randomly moves the stick. Okay, now we’re at 400.
Don: 400 and it’s getting a little bit more accurate.
Adam: It’s catching it. It’s getting it every time.
Don: It to intercept.
Adam: Yeah. Okay, so it feels like it knows what it’s doing, like it’s learned. And okay, then the, what is the, the overlay here says,
At this point, the agent finds and exploits the best strategy of tunneling and then hitting the ball behind the wall.
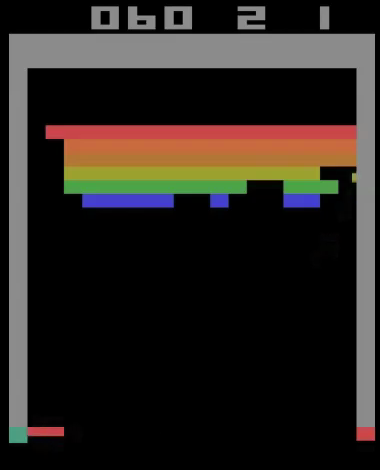
So it’s learned something after 600.
Don: It’s, it’s learned a strategy of trying to get in behind all the blocks because then… So it must be… So, because it’s counting the score, right? So it’s like if I can do this, then the score will go up more without my intervention.
Adam: Yeah. So it’s figured out this idea of like drilling a hole through all the blocks and then, then it doesn’t have to do anything, right? The ball just bounces around back there and clears things. That was like a huge deal. Like there was a paper in Nature and. It wasn’t just that game, right?
AlphaGo Takes On Go
Adam: After that DeepMind gets acquired by Google, which is nice because, Google, much like IBM, has just like a bazillion computers, the thing about this of training is you need something that can like play the games over and over.
Don: Great. You need the hardware.
Adam: You need the hardware. And so that is when they decide to tackle Go, right? Because I feel like if they were like, “Cool, we have this method. Everybody said it was no good, but we made it work. And we’re gonna tackle chess,” nobody would care. Chess has already been vanquished with this other tech.
Don: Nobody wants to hear about that anymore. That’s old news.
Adam: Yeah, we’ve moved on from that. So chess has already won, so they decided to do Go. And the, the thing about Go is it’s incredibly hard. So at that point, there was no good AIs at, at playing Go or, or very few.
Adam: The reason that goes interesting is because of this kind of exponential explosion. … When you play chess, there’s maximum like 35 moves you can make each game. And as we said, with Go, there’s much more, 250 possible moves at any point, which means if you’re trying to like play forward and build of that tree, it’s just astronomical.
Adam: It’s a very large board, you have a lot of pieces that you can place in lots of places, and then it takes a long time to play and it’s not till the end that it kind of all resolves and it’s like did you win or lose?
Don: Human players probably haven’t even moved those moves, right? Because there’s so many.
Adam: But humans are good at pattern recognition and somehow, you know, they learn to play this game and there are champions and, and they’re good at it. But it doesn’t seem to fall to our normal techniques of like, “Oh, let’s map this all out.” These reinforcement learning guys came in who had been listening to Sutton with his temporal difference… What is it again? Temporal.
Don: Difference learning.
Adam: Temporal difference learning. And they listened to him, right? And so they built their machine but there was this guy, Remy Coulom, … He was an AI expert and he had built the best Go program in the world. I think I have a quote from him.
Don: So the quote is:
I think maybe 10 years, but I do not like to make predictions.
Adam: So he said it would be 10 years, but then 22 months later they, they had beat this, right? AlphaGo beats the best Go players. That’s awesome. But like what is it, right? ‘Cause I’m a software developer.
Don: Yeah, you explained the problems with we can’t play the game to the end, like we don’t know what a good state is. So how does it make the decisions then on what… How did it quantify vibe?
Adam: Exactly. This is the question, right? And so I built, I built a version of Wordle. You know Wordle?
Don: Yes. I think everybody knows Wordle.
Adam: Yeah, I never really played it, but it’s my example. I built Alpha Wordle basically.
Don: So if you haven’t played the game, it’s a… Is a five-letter word that has been chosen that you don’t know what it is, and you’re trying to guess it. And you can put in a word, and it will evaluate your guess and tell you each letter, whether that letter is in the word and in the right spot, it’s in the word but in the wrong spot, or it’s not in the word at all.
Don: And given that feedback, you have to then pick a new word, and you only get a f- you know, a finite amount of guesses. I think in this one there’s, like, six. And then after six guesses, if you haven’t figured out the word, then you lose the game.
Adam: Here’s a, here’s a Wordle game we’re looking at. Let’s guess. So I don’t know, what should we guess? I’m gonna pick the word slate. When you play Wordle, you can do the same thing as in chess. You can say like, “Okay, if I play this move, there’s not an opponent, but I can get back a score,” right? And so if I get back and none of them match, then what I’ve eliminated not very many positions, but some.
Don: Because I mean, there’s a finite amount of position. It’s that it’s quantifiable now.
Adam: Yeah. So you can kind of play it forward in the same way you would with chess, right? So we’re looking at a Wordle game, right? And when I pick… So I’m gonna pick slate as my guess, and it was completely wrong. So it scored them…
Don: And none of those letters are in the word.
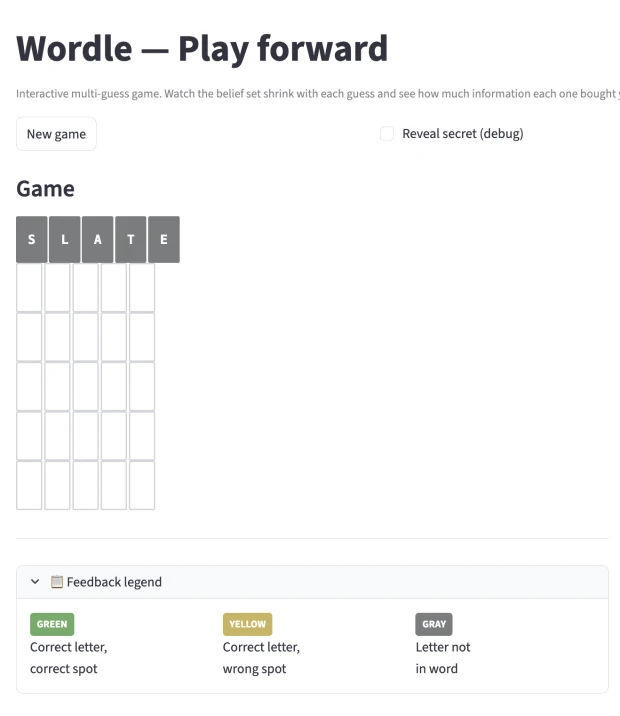
Adam: Yeah. And so there’s only a finite number of Wordle words, in their set, I guess there’s 2,315. So I played slight and nothing matched, but actually that eliminates a lot. So this is saying in my little app I made here, before this there was 2,315 possible words.
Don: Yeah, because you eliminated A and E, right? Which is contained in a lot of English words.
Adam: Yeah. And then I can play this forward, right? So say to, to go back to Go, right? At any given state in the game, I can tell how good I’m doing just based on how many possible words are left, and so that’s like the one component that’s hard in Go, right?
Adam: The other component is the playing forward. So now that we have the slate position, I can pick a new word. Let’s say if I pick this birch, but before I select it, right? So for any given word, I can do the same as in chess, right? I can search forward. So I know if I play the word birch.
Don: Oh, I see. Then you just be like, “Oh, if I get this result, then…” Yeah, that’s because the result here has a finite amount of possibilities. Yeah. Yeah.
Adam: Okay, so this is kind of, this is my dumbed down version of how the AlphaGo works, right? So it has this neural network, right? And in the neural network, the weights in the neural network are basically from playing the game through all the way to the end. The, the same as tic-tac-toe, and it figured out what won, and so it updated things, right?
Adam: And so for the game, for, for its playing, it thinks this word arose is like its best guess. Probably it played that word at some point and won, and so it’s like, “Oh, this is awesome,” right? So this is its best plays. And then it has this value which it calls position strength. So for Wordle, it’s saying, “My position strength is 3.644,” which is basically it thinks that it will win in.
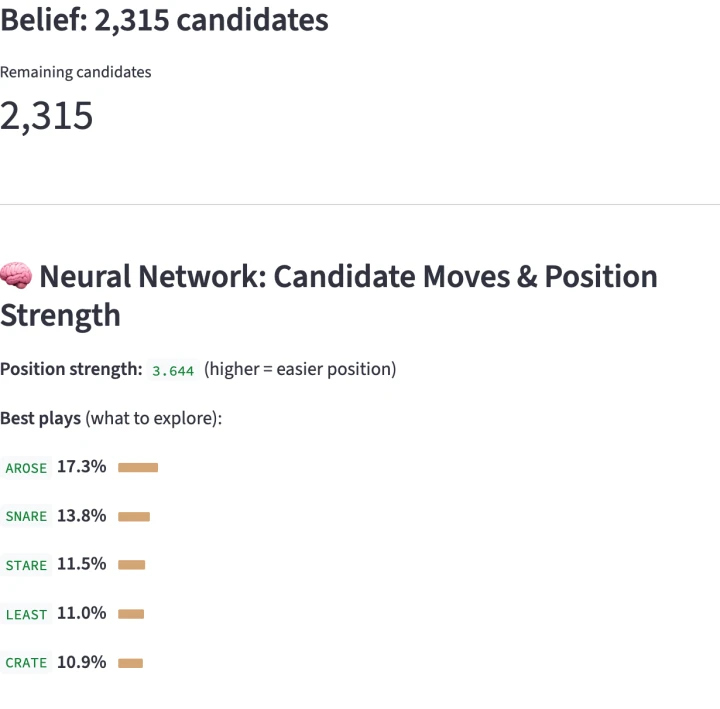
Don: About about three. Yeah, about three guesses. Or, or four. Three or four.
Adam: So this is, these are like the two important parts of the machine learning, right? It’s like it needs to know how good it’s doing. This is kind of like the chess points, right? And then this is kind of like what move to make. And so it thinks that we should do arose. How do we do arose?
Adam: But then the other important thing is we can play it forward in our head. So before we submit our move, we can kind of, okay, if I pick that, what are the possible options, right? So it thought this arose was best based on its original playing, but then when it plays forward from that position, it decides like, no, irate is better.

Don: Starting word? Yeah.
Adam: I’m gonna pick irate. So basically AlphaGo, they’ve combined these two ideas, right? So Deep Blue was this one idea, sort of let’s play forward into the future and figure out the values, right? Anytime it’s our position, we can kind of spread out and try to go quickly through all these rules and figure out what the best thing is.
Adam: With this, which is like then once we get to the end of the game, you know, we’ll learn from that and we’ll update these, which is kind of like Sutton’s tic-tac-toe. Does that make sense? It’s like they came up with this idea that we’ll have a neural network that tells us how good each position is, but how will it know that?
Adam: ‘Cause we said, oh, in Go it’s super hard to know actually if this is a good position or not. And so they said like, “Well, we’ll just, we’ll do the Sutton trick. We’ll, we’ll play a game of Go, and when we get to the end, we’ll say like, ‘Hey, if we won, all the places that that happened are good.’”
Don: So is this what sets him off and he’s, and he’s like, “Technical.
Adam: Temporal difference learning, yeah. Temporal difference learning. But that would take forever, right? The, to, to do that, ‘cause there’s just so many Go games.
Don: So you have to constrain how many games you play maybe.
Adam: Well, so you, you combine it with this other idea, which is the search, right? So when you’re playing your game forward, right? So I’ve played 10 games, right? And I have… So I think these 10 random moves I did are good, right? And then I’m going to play my 11th game, and before deciding what move to do, I’ll play forward.
Don: Yeah, like you play it, quote, “in your head.”
Adam: But we’re doing this two-stage learning, right? It’s like when we get all the way to the end, we say all these things must be good. And then when we’re playing in the future, we don’t wait until the end to decide if it’s a good move. We play it forward, and if it looks like any of the other ones that we did before, then that also must be good.
Don: Like if a piece of it matches one of the winning scenarios and you’re like, “Oh, this is a good one.”
Adam: This must be good, right? We’re learning faster. It’s like we don’t have to play all the way to the end of the Go so it’s this double layer thing. It took me a long time to understand this. Yeah. I mean, obviously it hasn’t learned everything, right?
Don: Obviously.
Adam: It’s playing like things that are not correct, but it can play this situation forward, right? And you can keep playing it, right? It can keep learning and it will get better. And in fact, like you can do this whole thing.
Don: Yeah, you’re like increasing the resolution of the prediction.
Adam: Wordle’s not that hard. You can actually just figure out the perfect Wordle move by walking through every game. It’s somewhat like Tic-Tac-Toe in that it has a bottom. So now it’s running a whole bunch of games and it’s learning more.
Don: You go.
Adam: He won.
Don: Yeah, you got it in the f- fourth guess.
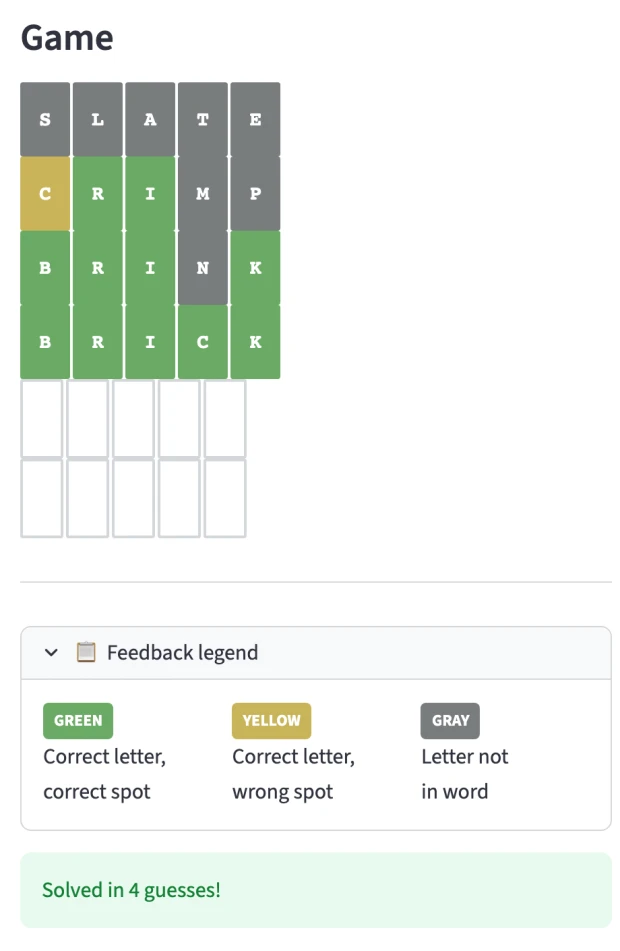
Adam: Eh, not bad. Not bad, AlphaWordle. This is their idea, right? And it took me a while to understand this. It’s like these two things, one is playing against yourself, or in the case of Wordle, there’s not another competitor.
Adam: It’s just like they’re just playing, but it’s still the same idea, right? It’s like thinking through the moves and updating it, and then this idea of searching forward. So they use, it’s called Monte Carlo tree search. But basically they’re randomly playing forward in this tree of words, and which moves they decide to play forward in are basically the ones they think are like, “Oh, this seems like a good move. Let’s play it forward a couple moves and see if it is.”
Don: It’s like limited foresight.
Adam: With some randomness, because it’s like you don’t just want to play the moves you think are good forward and see if they are, because you start off knowing very little and you’re probably wrong. So you have to.
Don: You have to fail a.
Adam: Yeah.
Don: Yeah.
Move 37
Adam: They do this and they train, and then, yeah, they’re gonna play this big game against this Lee Sedol, who’s the champion. Yeah. So they win the first game against him. At this time, it’s inconceivable that they win at Go, right? Like obviously we know that they won, but I was part of this thing called the Human Judgment Project at the time, and it’s like they tried to train experts bet on outcomes.
Don: Yeah, I remember you talking about that. It was because we both read that book about super predicting.
Adam: Yeah, super predicting, right? So I tried to join that guy’s project and you could bet on these things and this was one I bet, I was like, “There’s no way.” They’ve determined it will be like a million years before they’re good at this so I bet, no, Google will lose. And then they won the first game. Like they crushed them.
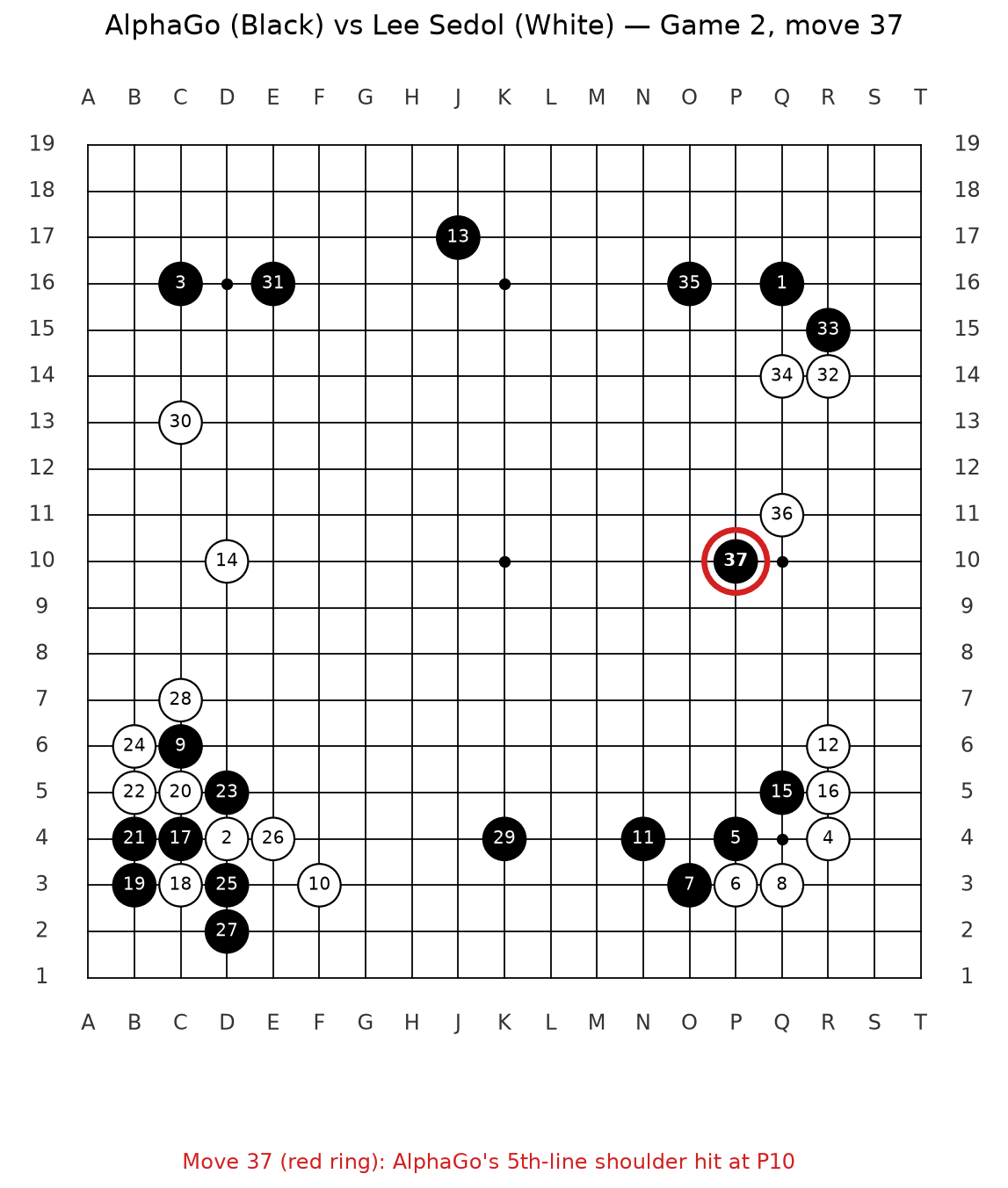
Adam: And then during the second game, I don’t know what’s happening, they’re playing out the moves and I don’t super understand things well. But AlphaGo is playing white and Lee Sedol is playing black [correction: AlphaGo had Black, Lee Sedol White] and it’s pretty early in the game, the position’s pretty open and the commentators, this is like a live broadcast thing, they say that Lee Sedol is, is doing quite well, maybe even a bit ahead.
Adam: But it’s still anyone’s game and it’s only game two so they don’t really know. So then AlphaGo plays a shoulder hit on the fifth line which I guess is like, “Oh.”
Don: Oh my God, a shoulder hit?
Adam: On the fifth line?”
Don: No.
Adam: Yeah. And so people don’t really know what to do. Yeah. So it doesn’t mean anything to me. I don’t know what a shoulder hit on the first line, but Go is like a 19 by 19 board and people put their stones down around…
Adam: And the, the basic rule you learn, right? It’s just like a basic rule is in the opening, in the middle, you play on the third and fourth lines. You don’t play on the fifth line. And so AlphaGo played on the fifth line, which is away from the center of the action, and I guess that’s for the end game.
Don: Yeah, I mean, we’d have to look up Go, Go terminology. But if it was doing that, there would have to be a, the, there would be a factor there would throw off the human competitor ‘cause they’ve never played against somebody that did that.
Adam: The same as the backgammon when the…
Don: Yeah, it’s like, “Wait, what’s going on?”
Adam: What are you doing?” So Lee Sedol who’s like, he’s the best at this. And so he only plays other, like, amazing, the best people. Yeah, what do you think he does?
Don: I mean, I think that he would probably… He doesn’t have a strategy for that because he hasn’t played against anybody who’s made those moves, so it wouldn’t– He would have to try and… No counter for it.
Adam: It’s funny ‘cause we know nothing about Go, so it’s like, But, I don’t understand the rules, but I assume they each have so much time to make a move, and what Lee Sedol does is he just gets up and leaves.
Don: He just left?
Adam: Yeah.
Don: He didn’t finish the game?
Adam: He just walked, like it’s a televised thing, and he’s like, “Oh.”
Don: Like why did he get out?
Adam: I mean, I’m sure he was just shocked. He didn’t know what to do. Like, you know.
Don: Wouldn’t you just keep playing? If I was playing chess against somebody and, you know, they made a weird, unconventional move, I’d just be like, “Well, I mean, I guess.” And then I would just playing with my own strategy.
Adam: And it’s a live broadcast thing and he left for 15 minutes, he just walks off and it’s not like they have, “AlphaGo, why don’t you entertain us?” No, that’s a computer, right? So the commentators on the live broadcast, they don’t really know what to say. They’re basically like, “I think this is a mistake. I think AlphaGo is off its rails. What should we do?”
Adam: And so an important thing, right, is AlphaGo has these two systems, right? It has the one that tells it the move it should make, right? And then the other one that we saw that kind of like plays forward what’s gonna happen, right? And so this, this weird move that it made, the thing that said what you should do next, basically said you should never do that, right?
Adam: But then they played forward the rules and all of a sudden it looked really. And so it was a rule, it was like it knew the same as we did or Lee Sedol knew, like this is not a conventional move, but then it played forward and it was like, “Hmm, interesting.”
Don: This is a good strategy.
Adam: Okay, and here is the architect of AlphaGo, who is actually David Silver. He was running the team at DeepMind. Here’s what he said was happening at that moment.
Don:
The professional commentators almost unanimously said that not a single human player would have chosen move 37. And then we found out that AlphaGo said that there was a one in 10,000 probability that a human player would have played that move. So it went beyond its human guide.
Adam: Then Lee Sedol comes back and he, he sits down. So I guess he isn’t gone. And they start playing. And like, yeah, the Go games are long. Like this was considered early games, but it’s move 37, right? But over the next 50 moves, everybody starts seeing what AlphaGo’s doing, right? This move starts to make sense and it, it starts to be like a dominant factor and they’re like, “Oh, I get it now,” right? It starts crystallizing in everybody’s mind who understands Go like, “Oh.
Don: Like a move now? Like now people like play to the outside or.
Adam: So he loses the game, right? And yes, I mean, I don’t know for this specific game, but I know that much like backgammon, the rules shifted. People start being able to play against these machines that have new techniques, and then they learn from them, right? It’s like we were based on our own strategies that we learned over time when we had these biases, but the computer’s out playing random games and discovers new things that we didn’t know, right? AlphaGo wins the match 4-1, so at least it’ll won one of them, right?
Don: 4-1’s pretty decisive though.
Removing the Humans
Adam: Yeah. And that was March, 2016. But people aren’t willing to give it up, right? And so this fact comes out that, okay, AlphaGo did actually have some human input into it. So there is this online thing called the Kiseido Go Server. It’s been around since the ’90s, and people play Go on it. Yeah, how many was it? Millions of games of humans playing that it had trained off.
Adam: So people were like, “Well, you said the machine has beat us, but maybe it’s just remembering, you know, user 5639 played move 37 on a Tuesday in 1993, and it’s just remembering it,” right? You see the same things with LLMs, right? They came up with a strategy to overcome this, which was, let’s do this again. Let’s build this again, but we won’t include the human’s play, throw it out, right? We’ll start again.
Adam: So it’s like the same machine as Wordle, right? It’s like if in my Wordle I originally played forward and I played a whole bunch of games, and then I start training it, and they’re like, “Oh, maybe it learned from me.” So then they do this again, they call it AlphaGo Zero. It’s a good name, zero because it’s like zero human knowledge. So now they play their AlphaZero against the one that beat him, and it crushes it. So they built an even better one.
Adam: And so this, the whole thing, playing all these games forward, it only took three days because they’re Google and they can just run so much in parallel and play all these millions of games at once. Which is, it’s kinda crushing, right? ‘Cause you could dedicate your life to being good at Go, and we’re like, “Well, we took this thing, didn’t even know what Go was.”
Don: Pigeon? They.
Adam: Three days later. Yeah, no, it’s just like we’re giving it a and it’s like Don in a box, so it’s like running at this super fast speed in parallel, and it learns. Here is how DeepMind announced it in the Nature cover in October 2017.

Don:
A long-standing goal of artificial intelligence is an algorithm that learns tabula rasa, a superhuman proficiency in challenging domains. Starting tabula rasa, the new program AlphaGo Zero achieved superhuman performance, winning one hundred to zero against the previously published champion-defeating AlphaGo.
Tabula Rasa was also a video game that Richard Garriott tried to… The guy who made Ultima Online. And it didn’t really get off the ground and then got scrapped.
Adam: Do you know what it means?
Don: Clean slate, I think. Yeah.
Adam: Yeah. A blank slate. Is…
Don: Slate.
Adam: Yeah, it’s like because it knew nothing, right? It started from absolutely nothing. Okay, so they removed the human games and it worked, but then they’re like, “Hey, we should remove more things,” right? Like what more can we remove? What do you think?
Don: What more can they remove?
Adam: So they did the Atari move. They basically removed the rules of Go. It doesn’t know how to play the game, much like my Wordle guy clearly.
Adam: Doesn’t know the.
Don: Know that you can’t play the same letter that you’ve already discounted.
Adam: So they’re like, what if it just all it can figure out, it just gets whether it won or lost.
Don: Yeah.
Adam: And then it’s like figures it out the same way the Atari thing did.
Don: So it just needs a win condition.
Adam: Yeah. And then once they built that version, they had it play a whole bunch of games. So they train it on Go, they train it on Shogi, which is some sort of Chinese chess-like game. They train it on chess. And so then they have it, like once they built their chess one, they have it play against Stockfish. And Stockfish is like the most powerful chess thing at that point that grandmasters learn against, and it’s got all this custom stuff. And then yeah, it crushes Stockfish.
Adam: And they’re making a point, right? They’re like doing the Sutton thing. I mean, I think they’re also drumming up publicity, but they’re like, “This thing knows nothing.” All it knows is whether it won or lost a game, and you can build the most complicated thing in the world, and you give me some time on Google’s compute things and a couple days, like we’ll crush you.
Adam: They’re making a very clear point, that they can just learn it all, right? … So that one was called Mu, Mu Zero, cause it doesn’t know any rules, like they’ve removed even more.
The Bitter Lesson
Adam: But, but meantime, since all this has happened, Sutton comes out and he writes kind of a manifesto. I feel like it’s, it’s always good when you can say, “I’m writing a manifesto.”
Don: A writing, sometimes they’re good, sometimes they’re bad.
Adam: Yeah, like he could go Unabomber. He could go.
Don: It’s risky.
Adam: Yeah. So he writes this short essay March 2019 that he posts on his personal website, and it’s three pages long, and he calls it “The Bitter Lesson.” And so for Deep Blue, right, the problem was that they had to have that evaluation function, right? They needed to be able to say like, how good is this chess position?
Adam: … You will hear people talk about the people who are big onto AI right now and who are building LLMs and all that, you’ll hear them talk about the bitter lesson all the time, and they’ll say things like, “Are we sufficiently bitter lesson pilled?” Basically, you know, in “The Matrix” where it’s like take the two pills? It’s like have we sufficiently taken the bitter lesson pill, right?
Adam: The bitter lesson that this one guy wrote has become like this important rule that all these people believe in, right? And so here’s how his three pages that becomes this big thing on his website opens.
Don:
The biggest lesson that we can read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin.

Adam: General methods, right? That leverage computation, that’s his whole point. I mean, it’s a larger essay, but he’s saying none of your clever methods, right? We don’t need 8,000 rules for how to evaluate a chess thing. We just do this tic-tac-toe thing. Just let it go. It has a reward, right? Like let it go, right?
Adam: But he means like large… When he says like a large margin, he means extremely large. Whatever you got, however clever you can be, building a complicated system, it will be beat if we can just figure out a way to get a reward signal and just turn the crank. It’s basically saying stop being clever.
Don: Yeah. Because computation has reached such a level that you just can provide it with a reward condition, then it can play out massive amounts of scenarios and create its own kind of guide, right? So you don’t need to actually provide it with any rules. Your rules might actually be constraints.
Adam: Move 37 or whatever it was, or.
Don: Yeah.
Adam: Backgammon thing that people are like, “That’s not the way you do it.” But they were right, Because Deep Blue had all these rules, but then, you know, Stockfish had less and was stronger, and then AlphaZero had no rules and like crushed it ‘cause it just, it can learn all the rules itself, right? It’s just simple algorithms, but they’re these learning meta algorithms. They win, right?
Adam: And so he was just… He was salty about this. He calls them sore losers, and he wins a Turing Award. And then he starts using this method everywhere, right? He uses it for, to get good at speech recognition. So there was like 30 years of building amazing speech recognition systems, you know, learning phonetic rules, and then people just come up with this deep learning method and just like, “Hey, we learned how speech works by just throwing lots of compute at.”
Adam: And then right in the middle, in a paragraph about Go, he says this thing that’s kind of summarizes this whole episode, right? This thing that I’m trying to get at. So read, read the next quote.
Don:
When a simpler search-based approach with special hardware and software proved vastly more effective, these human knowledge-based chess researchers were not good losers. Said that brute force search have won this time, but it was not a general strategy, and anyway, it was not how people played chess.
So learning by self-play and learning in general is like search in that it enables massive computation to be brought to bear. Search and learning are two of the most important classes of techniques for utilizing massive amounts of computation in AI research.
Adam: Yeah, because he’s saying a program can make its own data. We talked about this when we did the LLM episode, like, oh, they’re like, “We’re running out of data.” But here it makes its own data. You just let it run as long as it can figure out whether it’s one or lot.
Don: Yeah, you still have to provide it with good and what’s bad, right? What’s a positive and what’s a negative condition so that it knows how to evaluate.
Adam: And that idea, right, that came from Sutton. They were taking his tic-tac-toe idea. I mean, you have to squint and say like, “Well, maybe math.” They’re like, “Well, math could be like a tic-tac-toe thing,” right? We’ll just randomly guess and we’ll learn backwards.
Adam: But this is his idea, right? He’s finally, his, his brilliance has been recognized. There’s like 20 years of objections of his idea of self-play, right? But the bitter lesson, the reason he called it the bitter lesson, actually, you have the quote. Tell me why it’s called the bitter lesson.
Don:
We have to learn the bitter lesson that building in how we think we think does not work in the long run.
Adam: Which is super confusing. Building and how we think we think, but what he’s saying is like, don’t try to reflect.
Don: Ascribe your human conceptual models onto the AI because it doesn’t think the way that a human brain does.
Adam: Or it doesn’t need to, right? You don’t need to record the way the best chess player plays chess. You can just let it figure it out on its own, right? Don’t give it how we think we think. Just let it run.
Adam: And it’s bitter because, well, You know, you’re the greatest AI person or software developer, and you build this complicated system and all these rules, and it’s getting better and better, and he’s saying like, “No, actually, don’t be clever. Just throw compute and a reward at it, and it will be guaranteed better than whatever you can come up with.”
Adam: It’s a bitter pill to swallow to say like, “Whatever cleverness you can come up with, a human will not be as good as us just figuring out where the reward signal is and giving it unlimited compute,” right?
Adam: It’s kind of saying like, “Let the machine win.” Like, “The machine is better at this than you will ever be. Stop trying to teach it things. Just let it learn.”
Adam: So then October, 2021, in the Artificial Intelligence Journal, he publishes this thing that I texted you, right? Reward is enough. And so the people on this, one is, is Sutton, right? David Silver is the other person on it. He was the guy, the lead architect of AlphaGo and AlphaZero and AlphaMuZero, I think. But yeah, the last guy is Sutton, and it’s the same Sutton that’s all the way through. And in Reward is Enough, they, they make this claim, like even larger. Do you wanna read that?
Don: Yeah.
Reward is enough to drive behavior that exhibits abilities studied in natural and artificial intelligence, including knowledge, learning, perception, social intelligence, language, generalization, and imitation.
Adam: Now he’s definitively saying like, reward is not just enough for beating somebody at chess. Reward is enough for knowledge, for learning, for perception, for social intelligence, for language, for imitation, for… He’s basically saying that’s it. Like all of intelligence is contained in feeding something a reward and seeing what it learns.
Don: Yeah. I mean, again, it’s still reductive because we do undertake some endeavors not for rewards. I don’t think there’s a tangible reward to figuring out what dark energy is, but it’s something we haven’t discovered. How would you ascribe a win condition to that?
Adam: So Skinner, the, you know, was the… Skinner was a psychologist, and his methods got left behind a lot, although they were powerful because, you know, you think of Freud and wondering why people do things. Skinner never wondered about that. He was like, “No, you press the button, you get a piece of grain,” right?
Don: That’s enough for the, a pigeon, yeah.
Adam: But he had nothing to say about individuals and how they worked because people to him were like a black box, right? You give a reward and then the pigeon does the thing.
Don: People aren’t pigeons, right? We’re a little bit more complex.
Adam: But the interesting thing is these AIs are black boxes as well, right? We don’t know what’s going inside the neural net. Nobody cares. So it’s very interesting how it actually follows from this guy. He’s like, “I don’t, I don’t care what the pigeon thinks about it.” It’s like I trained it to do the bomb guiding. It’s like I don’t care what the neural network does.
Adam: Now it’s just better at chess than you will. And I don’t know, it’s many years later and he won the Turing Award and he, he wrote this, and it’s affected the whole world. But he went on this podcast about AI recently, 2025. He went on the Dwarkesh Patel podcast.
Don: Yeah, I, I… Know.
Adam: Yeah. He interviewed him ‘cause he’s like, “Oh my God, look at AI so big and you finally got your comeuppance.” You know, “What do you think? We’ve all finally learned your bitter lesson and we’re building these things.” Will you read it?
Don:
Large language models are about mimicking people doing what people say you should do. They’re not about figuring out what to do. They have the ability to predict what a person would say. They don’t have the ability to predict what will happen.
Adam: So they thought they learned all his bitter lesson, but he’s saying like, “No, man, you built an LLM by consuming all of human knowledge. That’s not AlphaGo Zero, right? You actually just built something that’s pretending to be human.” His way would be like.
Don: It starts with nothing.
Adam: By his thinking then we would be at the big blue era of AI, it’s really good at doing all these things, but it’s encoded all this human stuff, and the next step should be like, can we get rid of all the human stuff? ‘Cause right now the LLM isn’t gonna do the move 37, right? It’s trained on, on human knowledge.
Don: Yeah. It’s also trained on what it thinks you want. I think that he’s on the right for like a general artificial intelligence because he’s talking more about don’t teach it the content, teach it how to discover the content.
Adam: To learn.
Adam: Teach it how to learn. This guy who worked with him and who worked on the AlphaGo team, Julian Schrittwieser, he’s at Anthropic working on LLMs, building large language models. And he said, after that statement, he said like, “Oh no, you’re actually wrong, Sutton.”
Adam: Because as we discussed the other time, these LLMs have these RL loops in them now where they’re teaching them reward based on math and based on whatever. So he said, “No, actually, Sutton, you’re wrong. These LLMs are doing exactly what you’re saying.” I guess they’re built on human knowledge, but we’re still, we’re giving them this reward loop and they’re learning.
The Bitter Pill
Adam: Okay, but now I, I’m gonna go dark on this whole thing, right? Because I feel like this goes further than all of that, right? Because he’s saying, you know, reward is enough. Well, enough for what? He’s saying, well, it’s enough for everything.
Don: I think that there’s room for nuance there. I mean, most of the things we do have reward. Some things we don’t have a discernible reward.
Adam: Yeah. But.
Don: We eat to stay alive. We work to make money so we can alive, right? But there’s pursuits that don’t have any kind of discernible reward or reason why someone would do them.
Adam: It’s true. But I feel like what he’s saying is like if you can come up with a scoreboard, which is basically what the reward is, right? It’s like you need a way to score something, then the computers will, will beat you, right? And so it was easy to come up with a score for chess, and now the computers beat you at it.
Adam: Used to be this ImageNet, it was in the last episode, it was like identifying animals in images and computers couldn’t do it. But then they, they built this big dataset and they were like, “Get us to guess and say like, ‘Is this a cat? Is this a dog?’” Once they had that scoreboard, computers just learned and got better at it until they’re way better at identifying things in images than humans.
Adam: But now, there’s SWE-bench, right? It’s like a benchmark for programming tasks. It’s like you pull down this task and it’s like an open source bug and you have to solve it, and then it scores you on whether you’re good or bad. Problem is, that’s a benchmark that now a computer can do its reward game on.
Adam: And so the larger bitter lesson is like that we’re in trouble, if there’s a reward signal like the SWE-bench, a, a computer will be able to dominate us at it. That’s the dark version of reward is enough, is that reward is enough for a computer to, to crush you at, at what you do. And that’s the, that’s the bitter pill.
Adam: So for, for 70 years, the job was to be clever, right? I’m the best plumber at solving a problem or I’m the best software developer. But I feel like when I try to extend his analogy, it’s like Sutton’s whole life says that, these things are actually clever without us. Now that we’ve built them, the advantage of being clever is kind of escaping us. What, what’s valuable isn’t what you know anymore. It feels like the world’s changing. I don’t know. It, it feels bleak, right?
Don: I mean, it could, it could be, yeah. I mean, rewards are also dynamic. They change a lot. Sometimes, you know, what is today’s reward might be different tomorrow. By being able to redefine it, I think the thing is like when we work on something, we define the rewards. It comes from within our own kind of minds. Has yet to determine its own rewards.
Just Make a New Box
Adam: So that was the show. I know I exhausted Don. So he walked in not knowing… Actually, so I walked in not knowing what subserving meant. I had just never heard that term.
Don: Oh.
Adam: Yeah. Subservient I had heard, but I think we figured it all out.
Adam: Whether we agree with or not, I think is a little bit undecided. But yeah, thank you Don, for letting me go through this all with you. Here’s what I would say about Sutton. I think that he’s right. If you can come up with these rewards in this boxed system, the computer will win. But as humans, we just come up with new boxes.
Adam: And so this guy who did the backgammon right after the computer beat him at backgammon, he put out a new book, right? Or you invent a new game and the humans, you know, the way it is now, like we’re setting the limits of what these boxes are, right? And so I think you just have to keep learning and growing. If you try to compete head-on-head at a limited game with the, with the AIs that we have right now, you will be beat. But.
Don: Worry about it when it can create its own box.
Adam: Yeah. Yeah. You just make a new box, right? I’m not gonna try to write SQL, the most performant SQL anymore. I’ll just ask Claude Code, it’ll be better than me. But I’ll, I’ll, I’m building the things.
Adam: And yeah. So until next time, yeah, stay curious, learn new things. Time, thank you so much for listening.
Support CoRecursive
Hello,
I make CoRecursive because I love it when someone shares the details behind some project, some bug, or some incident with me.
No other podcast was telling stories quite like I wanted to hear.
Right now this is all done by just me and I love doing it, but it's also exhausting.
Recommending the show to others and contributing to this patreon are the biggest things you can do to help out.
Whatever you can do to help, I truly appreciate it!
Thanks! Adam Gordon Bell
